




Notebooks

Categories



Cells
Premium

BioTuring
Spatially resolved gene expression profiles are key to understand tissue organization and function. However, spatial transcriptomics (ST) profiling techniques lack single-cell resolution and require a combination with single-cell RNA sequencing (scRNA-seq) information to deconvolute the spatially indexed datasets.
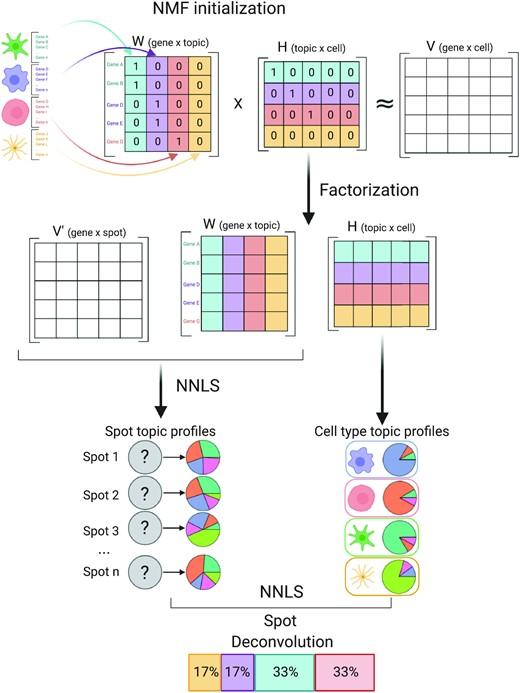
Leveraging the strengths of both data types, we developed SPOTlight, a computational tool that enables the integration of ST with scRNA-seq data to infer the location of cell types and states within a complex tissue. SPOTlight is centered around a seeded non-negative matrix factorization (NMF) regression, initialized using cell-type marker genes and non-negative least squares (NNLS) to subsequently deconvolute ST capture locations (spots).
Simulating varying reference quantities and qualities, we confirmed high prediction accuracy also with shallowly sequenced or small-sized scRNA-seq reference datasets. SPOTlight deconvolution of the mouse brain correctly mapped subtle neuronal cell states of the cortical layers and the defined architecture of the hippocampus. In human pancreatic cancer, we successfully segmented patient sections and further fine-mapped normal and neoplastic cell states.
Trained on an external single-cell pancreatic tumor references, we further charted the localization of clinical-relevant and tumor-specific immune cell states, an illustrative example of its flexible application spectrum and future potential in digital pathology.
BioTuring
Classification of tumor and normal cells in the tumor microenvironment from scRNA-seq data is an ongoing challenge in human cancer study.
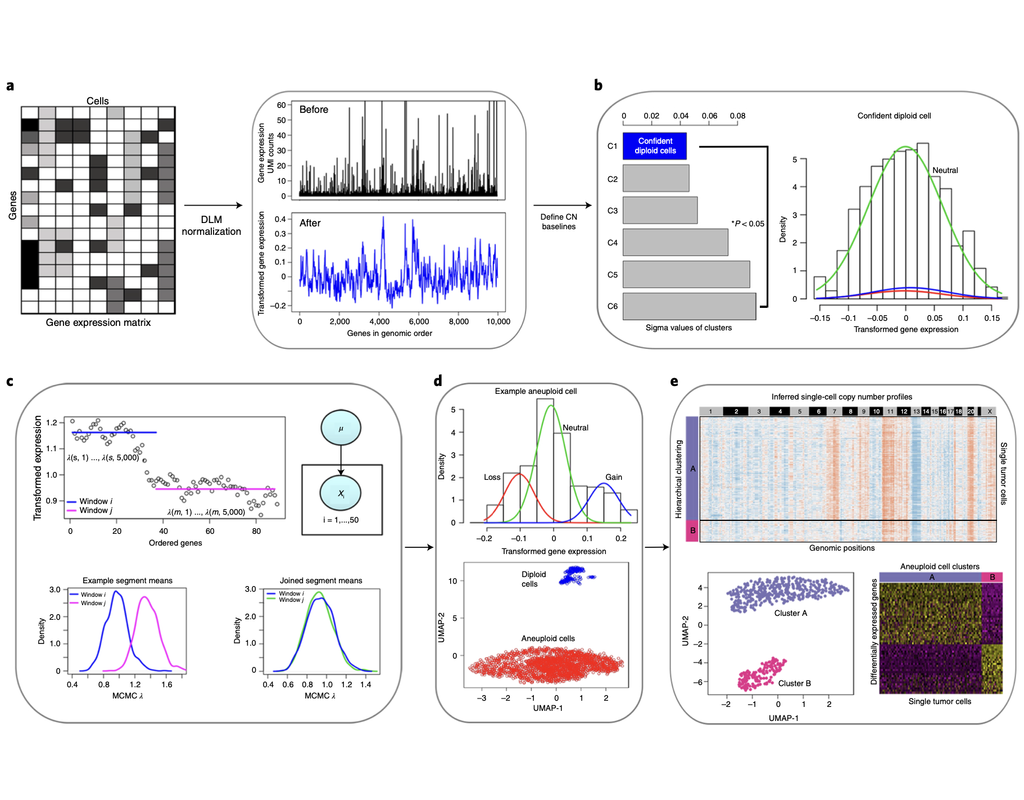
Copy number karyotyping of aneuploid tumors (***copyKAT***) (Gao, Ruli, et al., 2021) is a method proposed for identifying copy number variations in single-cell transcriptomics data. It is used to predict aneuploid tumor cells and delineate the clonal substructure of different subpopulations that coexist within the tumor mass.
In this notebook, we will illustrate a basic workflow of CopyKAT based on the tutorial provided on CopyKAT's repository. We will use a dataset of triple negative cancer tumors sequenced by 10X Chromium 3'-scRNAseq (GSM4476486) as an example. The dataset contains 20,990 features across 1,097 cells. We have modified the notebook to demonstrate how the tool works on BioTuring's platform.
BioTuring
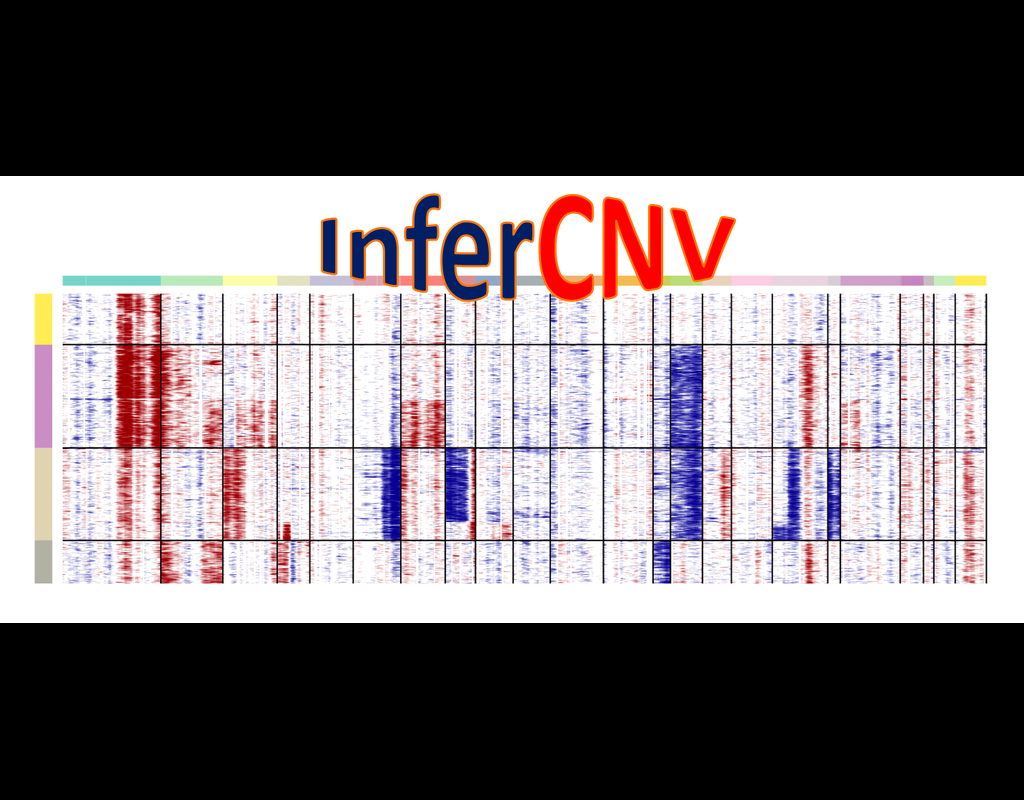
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
BioTuring
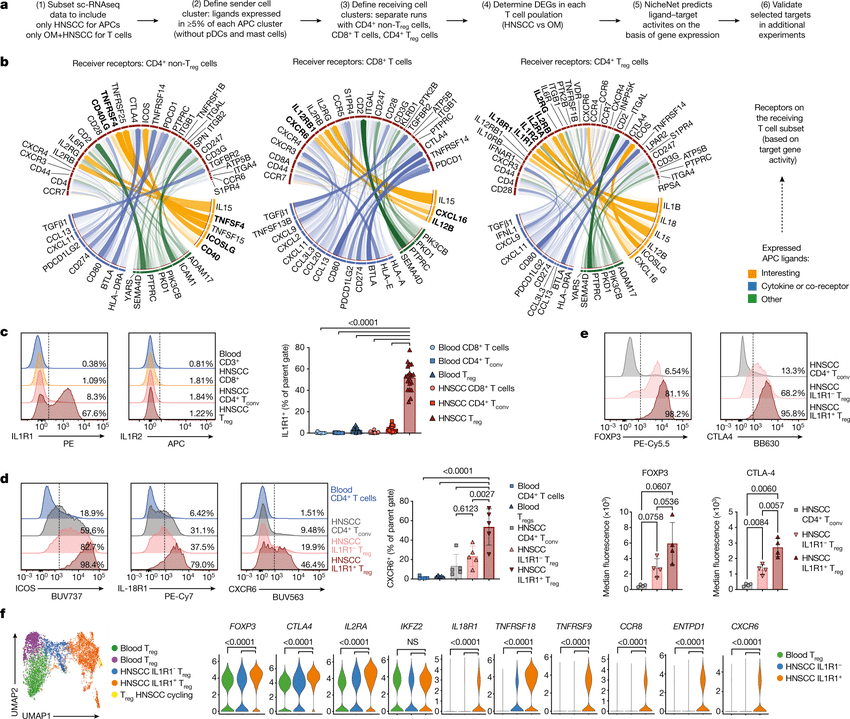
Computational methods that model how the gene expression of a cell is influenced by interacting cells are lacking.
We present NicheNet, a method that predicts ligand–target links between interacting cells by combining their expression data with prior knowledge of signaling and gene regulatory networks.
We applied NicheNet to the tumor and immune cell microenvironment data and demonstrated that NicheNet can infer active ligands and their gene regulatory effects on interacting cells.
Trends
BioTuring
The development of immune checkpoint-based immunotherapies has been a major advancement in the treatment of cancer, with a subset of patients exhibiting durable clinical responses. A predictive biomarker for immunotherapy response is the pre-existing(More)