




Notebooks

Categories



Cells
Premium

BioTuring
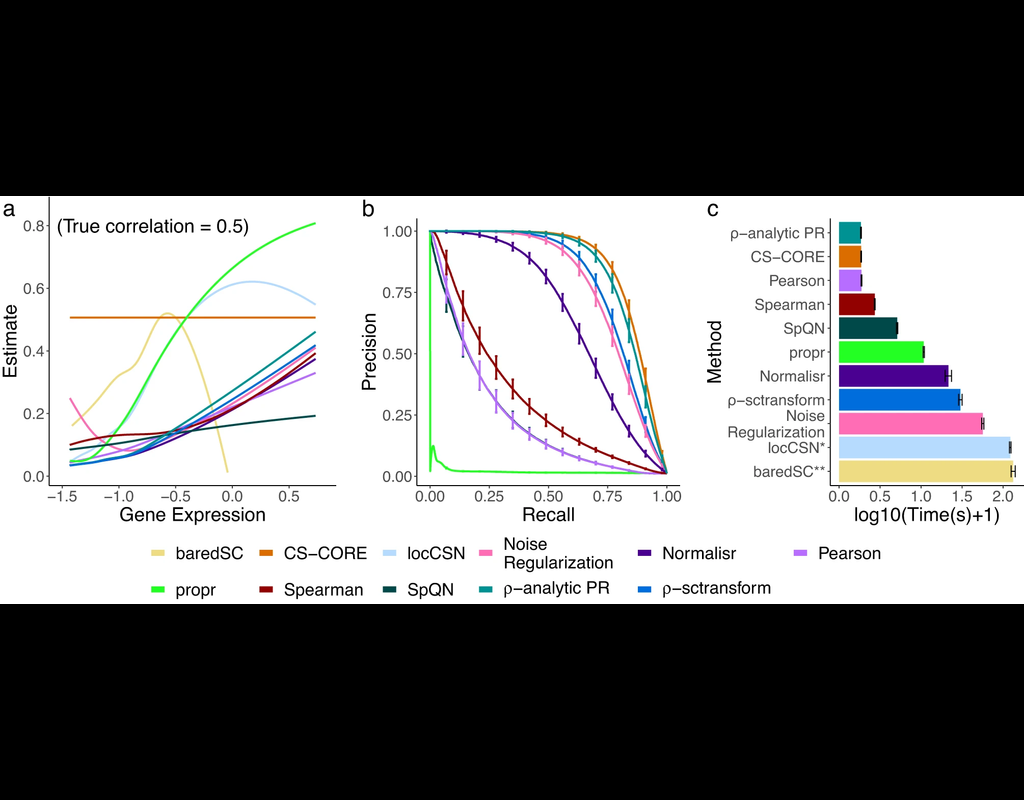
The recent development of single-cell RNA-sequencing (scRNA-seq) technology has enabled us to infer cell-type-specific co-expression networks, enhancing our understanding of cell-type-specific biological functions. However, existing methods proposed for this task still face challenges due to unique characteristics in scRNA-seq data, such as high sequencing depth variations across cells and measurement errors.
CS-CORE (Su, C., Xu, Z., Shan, X. et al., 2023), an R package for cell-type-specific co-expression inference, explicitly models sequencing depth variations and measurement errors in scRNA-seq data.
In this notebook, we will illustrate an example workflow of CS-CORE using a dataset of Peripheral Blood Mononuclear Cells (PBMC) from COVID patients and healthy controls (Wilk et al., 2020). The notebook content is inspired by CS-CORE's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
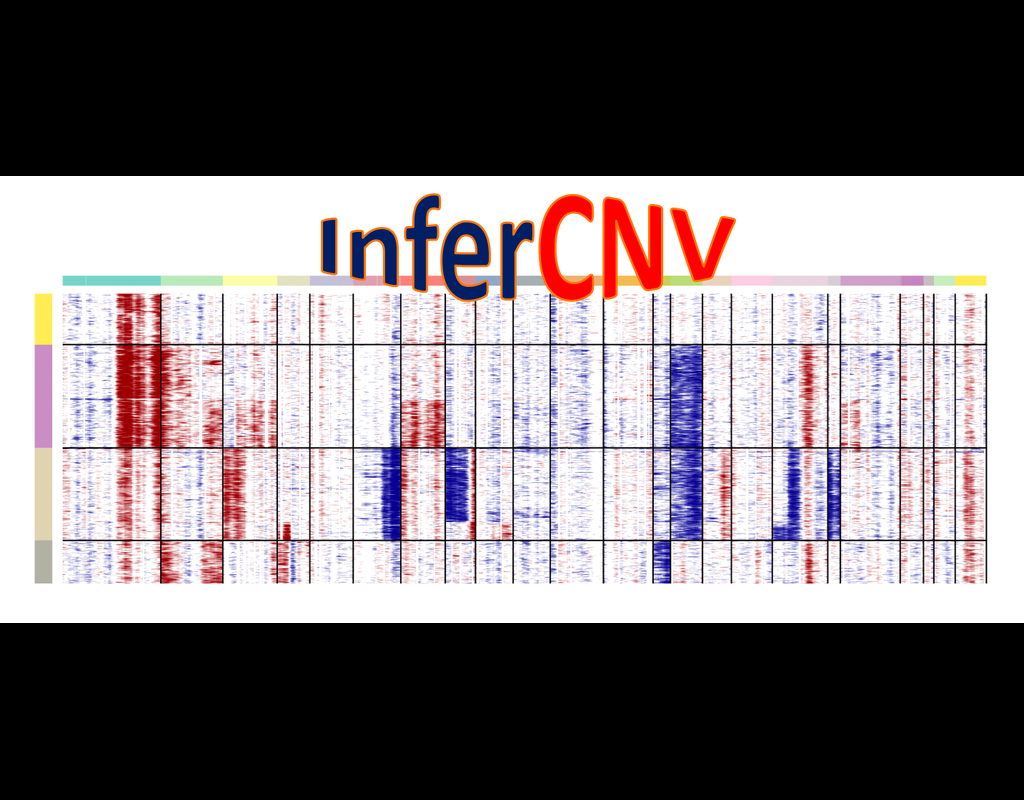
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
BioTuring
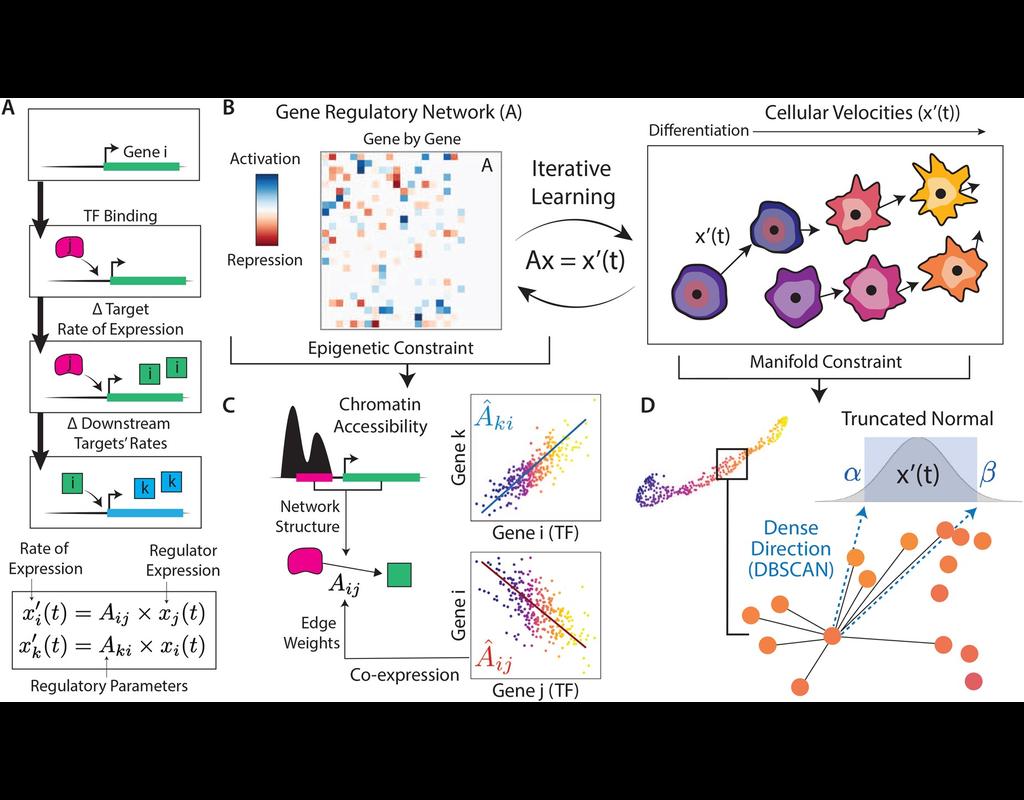
In the realm of transcriptional dynamics, understanding the intricate interplay of regulatory proteins is crucial for deciphering processes ranging from normal development to disease progression. However, traditional RNA velocity methods often overlook the underlying regulatory drivers of gene expression changes over time. This gap in knowledge hinders our ability to unravel the mechanistic intricacies of these dynamic processes.
scKINETICs (Key regulatory Interaction NETwork for Inferring Cell Speed) (Burdziak et al, 2023) offers a dynamic model for gene expression changes that simultaneously learns per-cell transcriptional velocities and a governing gene regulatory network. By employing an expectation-maximization approach, scKINETICS quantifies the impact of each regulatory element on its target genes, incorporating insights from epigenetic data, gene-gene coexpression patterns and constraints dictated by the phenotypic manifold.
BioTuring
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows statistical strength across locations, thereby enabling the integration of single cell and spatial transcriptomics with higher sensitivity and resolution than existing tools. This is achieved by estimating which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
This tutorial shows how to use cell2location method for spatially resolving fine-grained cell types by integrating 10X Visium data with scRNA-seq reference of cell types. Cell2location is a principled Bayesian model that estimates which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
Trends
BioTuring
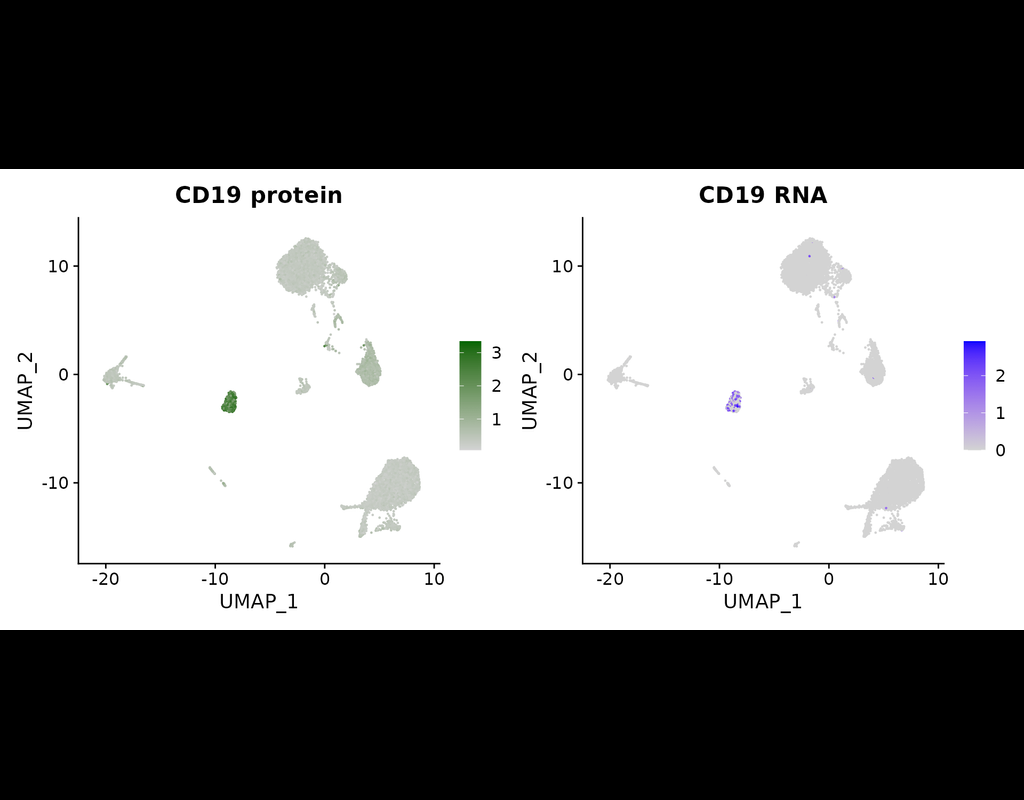
The simultaneous measurement of multiple modalities represents an exciting frontier for single-cell genomics and necessitates computational methods that can define cellular states based on multimodal data.
Here, we introduce "weighted-nearest nei(More)